
Crawling and Indexing, are automatic processes of “Googlebot” and this process is known as Google Search. This is also known as the Spider bot. Spider bot explores the internet world daily and indexes millions of new pages. The function of the crawler is automated and explores daily to find new URLs to find new pages for indexing.
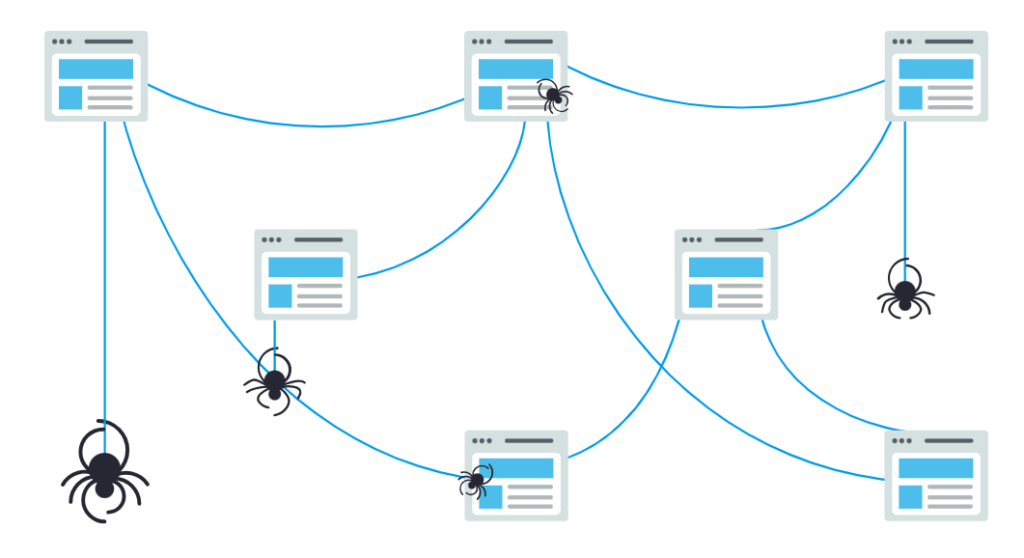
Indexing refers to storing new or updated pages in a cloud database, for redirecting users according to related queries. Google search is an automatic process that refers to crawling and indexing new pages without any inclusive request or manually. Googlebot optimized the page automatically and ranked the pages accordingly, in the search results.
This blog helps you to understand, an in-depth knowledge of how Google search works. A good understanding of this fundamental knowledge helps, you to fix crawling and ranking-related issues.
This blog will also help website developers integrate the necessary steps to boost sites’ performance. Implementation of Robot.txt. And other files to control indexing and crawling. However, several types of Google crawlers are actively fetching data and information from millions of sites daily. Let’s begin.
Three Stages of Google Search
According to Google, there are three stages of Google search. This means among all the pages only a few of them pass through these three stages of Google search. However, this is the primary reason for failing to rank your website in Google searches. Thus, it’s an important step to take as a priority while planning a digital marketing strategy.
- Crawling; refers to following good-quality URLs (links) to find new pages or updating the database with old and updated pages.
- Indexing; refers to storing new pages and updated pages, in a large database irrespective of the queries from users.
- Serving Search Results (Keyword queries) is a process, where Google provides thousands of information pages according to the queries.
Understanding Stages in-Depth
Still, various other factors are responsible for the ranking of a website. However, these three stages of Google’s quest are areas of focus, before the other factors. Therefore, discuss these stages in detail.
Serving Search Results of Google Search
The first process involves a user search for a query, “Googlebot” redirects to the index (google database) searches for the best quality, informative page, and returns with the most relevant information available. The relevancy of the information (content) depends on many factors but the topmost are users’ location, language, and device.
It depends on the region where the user lives according to the keyword relevancy, google bot can show results from other areas. It also depends on how a user asks (grammar) about a particular information (better grammar = better accurate results).
According to the user’s requested search query, the search feature changes its appearance in the search result. For example; assume someone searches for “Beautiful flower shop”, the search engine will show results without any images, whereas, searches for “Beautiful boutique shop” may show image results but not nearby. You can customize your visually attractive website designs at eternitty.com on how your website will appear in the search results.
To know, whether your website is indexed or not you can use tools like Google Search Console. However, it won’t tell you whether your site will appear in the search results. If your site won’t appear on the search result then because of these three problems.
- Poor content quality
- Content doesn’t have keyword relevancy
- Robot meta-rules disrupting crawling
Crawling of Spider Bot
Google bot continuously fetches new and old updated pages as it doesn’t have a central registry element. The priority of the spider bot is to look for good URLs, scan good content pages, and spam content to add them to the list of credible pages. “URL discovery” is the process of continuous improvement and finding new pages daily.
Spider bot remembers the visited page and thus, has a higher appearance in the search result. Now! Here is the secret; “Spider bot only discovers and indexes those pages while it can follow the link from a known visited page to a new page“. It all starts with your website thus, it’s necessary to know all the essential elements to create a perfect well-integrated SEO website for example, check out our web design services at eternity.
Here, submitting a sitemap of your site helps the Google bot to recognize the visited site for credibility and track the URL to a related new page. This is how Googlebot indexes and finds pages. Google uses a humongous computer network to maintain all these operations. Once a Google bot discovers your page’s URL, it scans the page for its content relevancy and quality of keywords. It uses an automated algorithm to conclude the number of crawling processes for each site and page.
Spider bot is intelligent and knows when to stop and how to continue to prevent overloading while crawling. The process of this mechanism is based on the response of the site’s working status for instance HTTPS 500 error “mean slow down”.
Spider bot can discover all the pages in real-time but may not crawl all the sites. This is because of more than one reason.
- Using robot.txt. Or no index files to disallow the bot from crawling
- poor SEO configuration
- The site is not logged in
- server error
Spider bot use rendering process to know about the page content. It may run a JavaScript to check according to the new Chrome feature, to check accessibility. Rendering is the sense of a Google bot, it renders to find any JavaScript to run because some may use JavaScript to bring content to the page. Without rendering google is blind to text.
Indexing of Pages
This is called the analyzing stage. Spider bot first crawls to analyze the page content and what it’s all about. Google bot tries to understand the page content by following some breadcrumb trails to store the page and rank it accordingly. This process of analysis and storing a page after crawling is known as Indexing. Spider bot analyzes the textual content and scans some content tags thus, the content must be grammatically correct and follow a proper SEO content rule.

Clustering is a process during indexing. Through “clustering” Google differentiates between the copied pages and canonical pages, canonical pages are the pages that appear in the search result. Clustering is a process that helps to show the most relevant content to the query. The other related contents are used in different contexts for example if the users were searching from various devices or looking for a specific page from the cluster.
Therefore, Google also gathers extra information or signals like the language of the content, the type of the content, the country, or the local area, and last but not least the usage ability of the recognized or canonical page which prepares for the next stage.
Google Index stores all pieces of information related to cluster and canonical pages. Thousands of computers host a pile of data, but google itself! cannot Index every page. Moreover, Indexing has its limitations. It depends on metadata, content quality, and relevancy of a canonical page. Additionally, Indexing has common problems like
Indexing becomes difficult based on the design of the website, the quality of the webpage, and the content, the algorithm of meta/robots does not allow to Index.
Conclusion
For a layman, it’s a simple process of searching for an item by typing in the search box. However, there are a lot of complex processes like crawling, indexing, and clustering to serve the searched query to the user.
It all starts with Google Bot or Google Search. The bots scan the query and then look for the relevancy of the query with the content irrespective of the grammar to be more accurate in the search. Additionally, a Google Bot applies the process of crawling, indexing, and serving the searched query depending on the relevancy of the content.
Moreover, crawling and indexing is an endless process of gathering the pile of information and storing the pieces of information in thousands of computer-like books in a library. Then, the user types the query in the search box and commands the bot to serve the searched content. Again, the bot crawls the recorded data and also the new data and indexes it according to the accuracy and relevancy of the asked query to the crawled content, then the search bot clusters the indexed content to index it further into canonical and duplicated content, at last the bot serve the most relevant and the best quality of content to the user.
Therefore, even before a user’s request to search, the bots continuously perform the three stages of Search as mentioned above, crawling and indexing.
Rendering is how spider bots learn about the content of the pages. Following the new Chrome feature, it might execute JavaScript to verify accessibility. A Google bot’s rendering process looks for any JavaScript that must be run because certain websites use JavaScript to add content. Without rendering, the text is invisible to Google.
This is the detailed function of Google search.
